排序
Posted on In 数据结构与算法
根据给定的值,在查找表中确定一个关键字等于给定值的数据元素。
查找表可以分为两类——静态查找表和动态查找表(查不到要增加,或者查到了就删除)
平均查找长度:也称为平均比较次数。
也就是遍历查找
每次循环中都要判断是不是越界了,就影响效率,优化是把关键字放在表头,到头了就得到关键字,省去了每次查找的判断越界。
建立索引,索引指向目标附近。
适用情况:快速查找且动态变化的表。
二叉排序树满足以下条件:其左树的子节点值均小于该节点,右树的子节点值均大于该节点。
查找直到某个叶子节点的左子树或者右子树为空为止,然后将该节点插入为该节点的子树。
一个平衡二叉树,在增加一个节点之后,可能发生失衡,这时候就需要调整节点关系,使二叉树保持平衡。
具体操作不好文字描述,略。
记录哪些点访问过
邻接矩阵时间复杂度为O(n**2),适合访问稠密图
邻接表时间复杂度O(n+e),适合访问稀疏图。
从起始点开始,访问他的一级邻居,然后访问他的二级邻居,以此类推。
与深度优先相同。
生成树:不存在回路的连通图
无向图的生成树:遍历时通过的边组成的集合
最小生成树:在一个网络中,在所有生成树中,使得各边权值之和最小的生成树,也叫最小代价生成树。
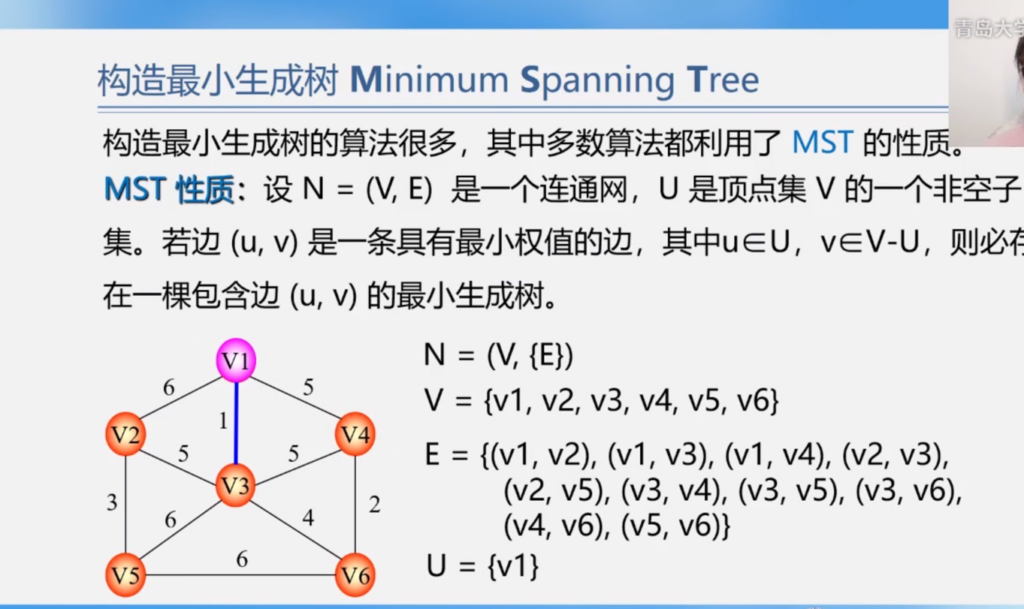
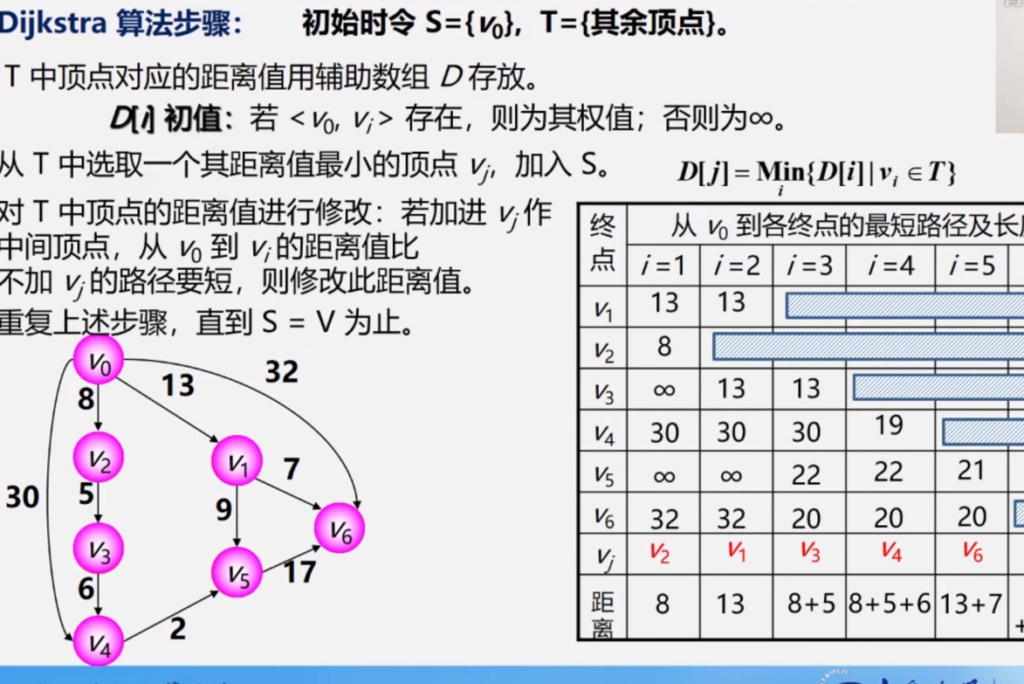
构建最小生成树的方法,使用贪心算法,每次总是选择两个集合之间权值最小的边,一步步构筑最小生成树。
时间复杂度:O(n**2)
更直接的贪心算法
直接叫所有顶点组成一个集合,在所有的边中从小到大添加到集合中,若形成环则跳过这个边,直到所有的顶点都联通。
时间复杂度O(e)
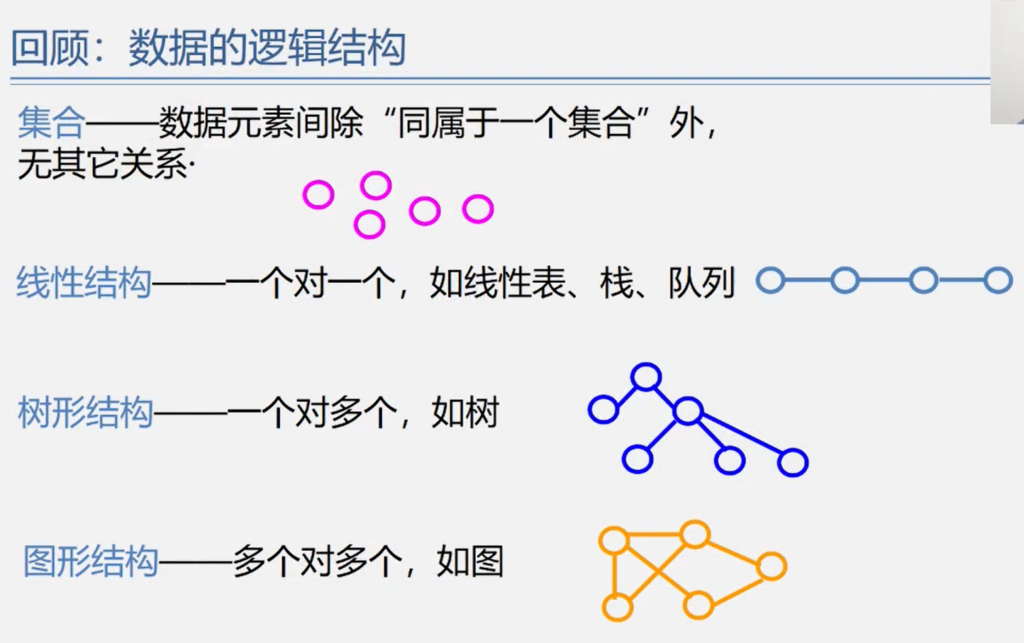
四种逻辑结构
G=(V,E)
Graph=(Vertex,Edge)
图=顶点的有穷集合+边的有穷集合
无向图/有向图
完全图/稠密图/稀疏图
网:边/弧带权的图
顶点的度:与该顶点关联的边的数目,在有向图中则细分为入度和出度
路径:持续的边构成的顶点序列
连通图:任何两顶点均存在路径
子图:顶点集合或者边为父图的子集合的图
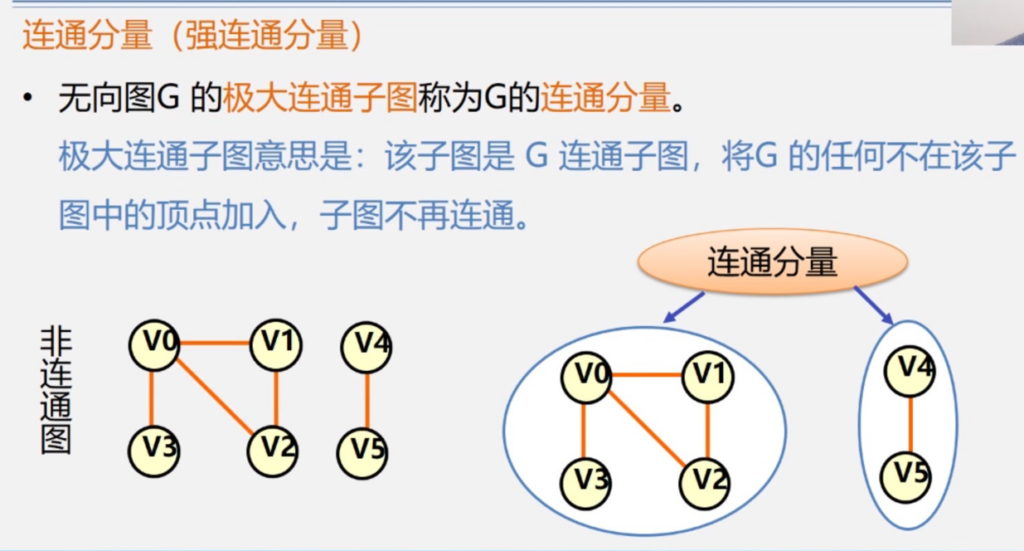
可以说是很不说人话了
人话就是,彼此不相连的,不可分割的个体。
分为深度优先遍历和广度优先遍历,后面展开讲
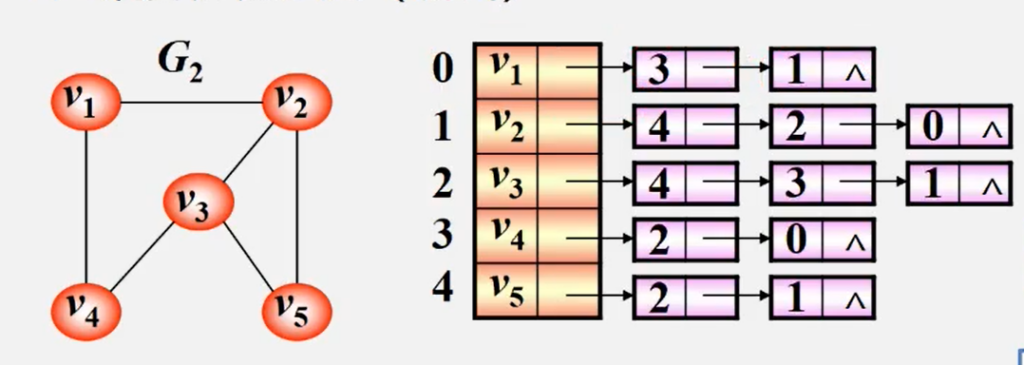
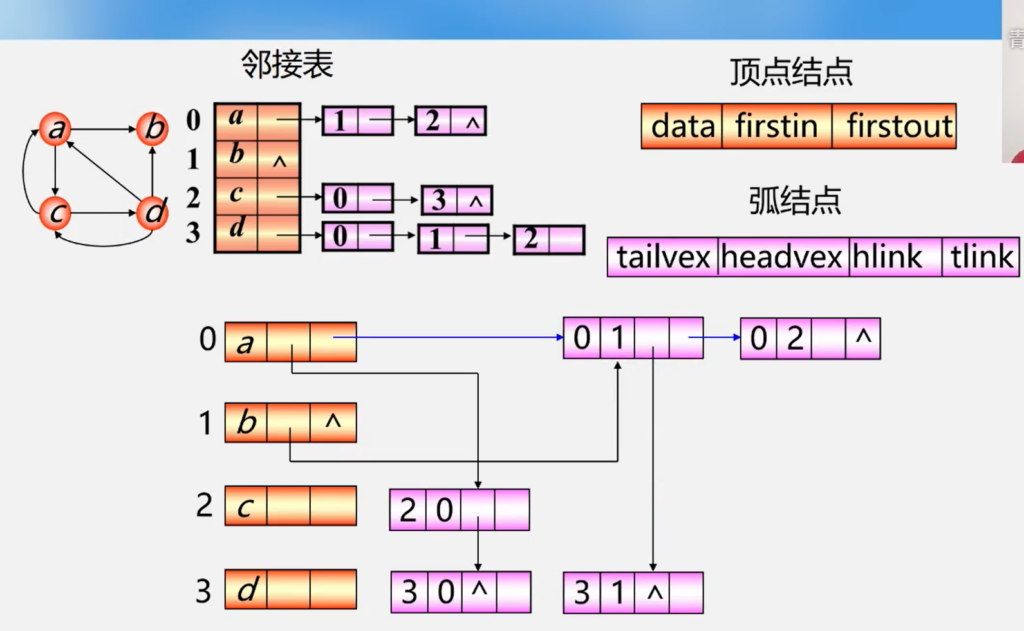
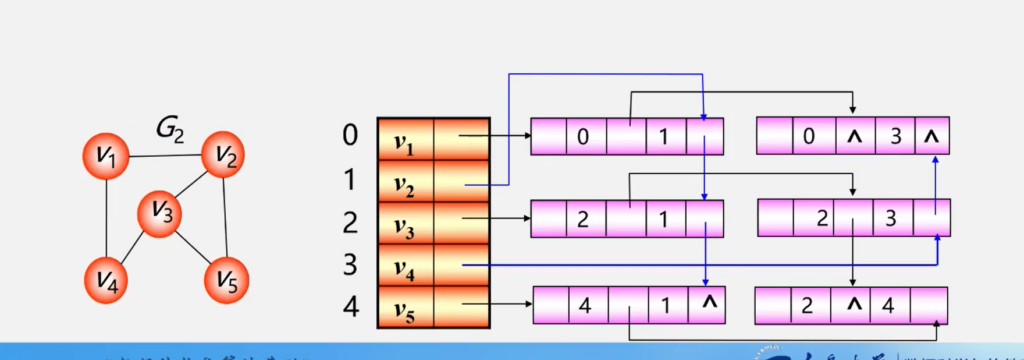
建立一个顶点表存储顶点信息,再建立一个邻接矩阵记录个顶点的关系(也就是边或者弧)