01背包问题
参考
参考自https://www.cnblogs.com/wl-blog/p/14913905.html,这篇讲的很清楚。
先上代码:
1 | # N = 4 |
大致思路:
一个背包在只能选择n-1个物品时达到了最优解,如果此时可以选择第n个物品了(假设剩余容积可以放下该物品),那么最优解就可以分成两个可能:选择第i个物品和不选择第i个物品
于是就可以通过定下初始条件进行递推
1 | # 状态转移方程 |
如果不选择第i个物品,那么最大价值和f[i-1][v]相同
如果选择第i个物品,最大价值=容量为v-w[i]时的最大价值(最优解)+i物品的价值
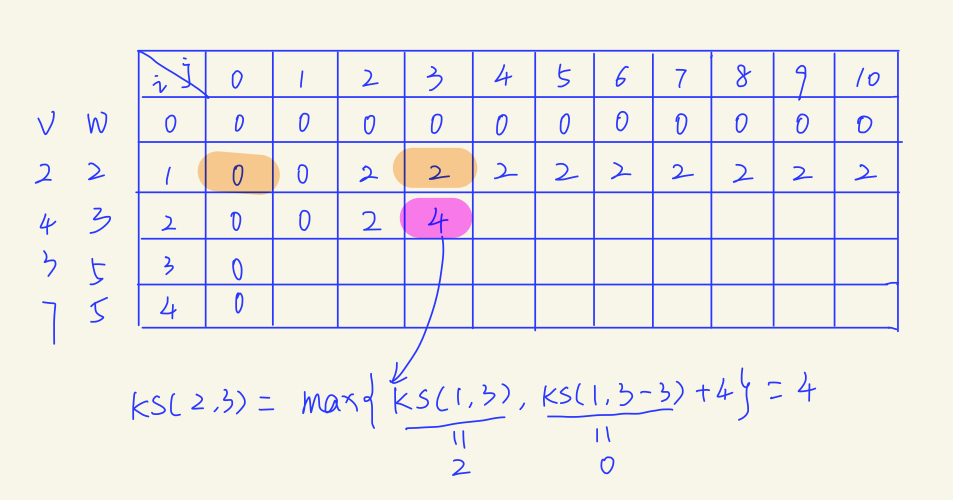
好图,偷了
数据结构与算法·其七
栈
栈的抽象数据类型
顺序栈的抽象类型
1 | #define MAXSIZE 100 |
顺序栈的一些算法
- 判断是否为空
- S.top == S.base ? true : false;
- 栈长度
- return S.top-S.base;
- 清空栈
- if(S.base){S.top=S.base}
- 删除栈
- if(S.base){delete S.base; S.stacksize=0;S.base=S.top=Null}
- 压栈
- 判断是否满了->栈顶上移,写入e(*S.top=e;S.top++;)
- 出栈
- 判断是否为空->获取栈顶元素->栈顶下移
链栈的抽象数据类型
只能在链表头部进行操作的特殊链表
特点:
- 不需要头节点
- 头指针就是栈顶
- 空栈就是头指针指向空
- 插入和删除仅发生在栈顶
算法
- 入栈
- 新建一个节点,指针域指向上次的栈顶,修改栈指针
- 出栈
- 头指针指向下一位,返回上次的*S.top
栈与递归
递归
如果一个对象部分地指向自身,或用自己给自己定义,那么他就是递归的
如果一个过程直接的或者间接的调用自身,那这个过程是递归的过程
递归工作栈
在函数嵌套调用或者递归时,所有进行中的函数都被保存在栈内存中
递归的优缺点
- 优点是程序简洁易读
- 缺点是每次调用要生成记录,保存状态信息,稍后要取出状态信息,时间开销大。

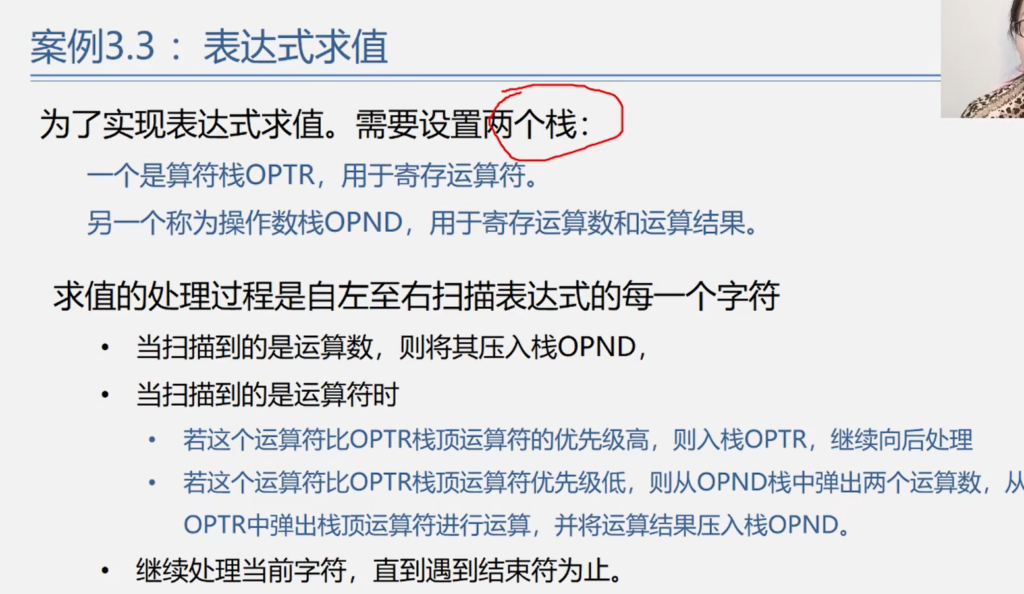
数据结构与算法·其五
循环链表
好处是从表中任意一点出发均可找到表中其他节点
遍历操作的终止条件是p!=L
循环链表的合并
将a表的尾节点指针域指向b表的第一个节点;b的尾结点指向a表的头节点;释放b表的头节点;
双向链表
具体算法
- 插入元素(在i位置之前插入元素e)
- if(!(p=Getelemp*Dul(L,i))) return ERROR;*找到要被插入的节点_
- S=new DulNode;S->data=e;
- S->prior=p->prior;p->prior->next=S;
- S->next=p;p->prior=s;
- 删除元素
- 略
双链表更方便了,但是存储空间更大,插入元素要修改更多的指针。
各种链表的时间效率比较
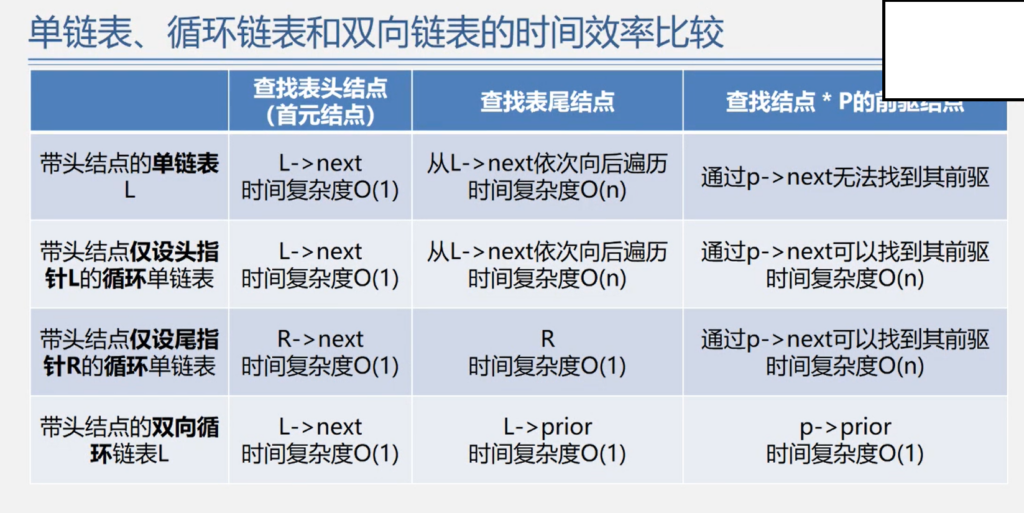
链表的使用场景是需要频繁增加删除元素;
顺序表的使用场景是不经常增删,却经常改查;
数据结构与算法·其四
链表
链式存储结构
每个元素在存储器上的位置是任意的,逻辑相邻并不一定物理相邻。
每个节点存储的数据有两个部分。数据域和指针域。
访问时只能通过头节点依次向后查找,这种方法称为顺序存储法
如何判断链表是否为空
- 有头节点,头节点的指针为空时;
- 无头节点,头指针为空时;
链表种类
- 单链表:指针域只存储下一个元素的位置
- 双链表:指针域存储上一个和下一个的位置
- 循环链表:链表结点首尾相接
具体算法
- 初始化
- L=new LNode
- L->next=Null
- 销毁
- while(L){p=L;L=L->next;delete p;}
- 清空
- p=L->next;while(p){q=p->next;delete p;p=q;}L->next=NULL;
- 相比较于删除操作,仅仅保留了头节点
- 获取表长
- p=L->next;i=0;while(p){i++;p=p->next;}return i;
- 获取第i个元素
- p=L->next;j=1;while(p&&j<i){p=p->next;++j}if(!p||j>i)return ERROR;e=p->data;return OK;
- 按值查找
- p=L->next;while(p&&p->data!=e){p=p->next}return p;
- 插入节点(在第i个元素之前插入数据e)
- p=L;j=0;
- while(p&&j<i-1){p=p->next;++j;}
- if(!p||j>i-1)return ERROR
- s=new LNode;
- s->next=p->next;p->next=s;return OK;
- 删除节点(删除第i个元素)
- p=L;j=0;
- while(p&&j<i-1){p=p->next;++j;}
- if(!(p->next)||j>i-1)return ERROR;
- q=p->next;p->next=q->next;
- delete q;return OK;
数据结构学习笔记·其三
线性表
线性表是具有相同特征的数据元素的一个有限序列。
特征:
- 只有一个开头,一个结尾
- 元素具有相同特征
顺序存储结构
相当于数组的模式
顺序存储结构存在的问题:
- 存储空间分配不灵活
- 运算的空间复杂度高
链式存储结构
在每个元素内存储与它相邻的两个元素的位置
线性表的操作(ADP)
- 初始化线性表
- 销毁线性表
- 清空线性表
- 判断线性表是否为空
- 获取表长度
- 获取表的某个元素
- 定位元素的位置
- 获取当前元素的前驱/后驱
- 插入元素
- 删除元素
- 遍历元素
线性表的顺序存储结构表示
顺序存储:
把逻辑上相邻的结构存储到物理上相邻的存储单元
顺序存储的特点:
- 占用连续的空间,中间不得出现空位置
- 根据某个元素的位置可以推出其他元素的位置
顺序存储结构的定义:
- 最大长度
- 数组长度
- 元素
顺序存储结构操作方法:
- 初始化线性表
- 分配存储空间,分配失败返回错误
- 设置length为0
- 销毁线性表
- 释放存储空间,若数组不存在则返回-1
- 清空线性表
- 设置length为0
- 判断线性表是否为空
- length==0?return true:return false;
- 获取表长度
- 返回length成员
- 获取表的第i个元素
- 判断i是否合理
- 返回L.elem[i-1];
- 定位元素x的位置
- for(m,index in L){if(m=x){return index}};return -1;
- 平均查找长度就是期望E(x);
- 插入元素
- 判断插入位置是否合法
- 判断空间是否已满
- 将第n到第i个位置的元素从后到前依次位移来腾出空间(这一步占据了最多的时间)
- 将新元素放在第i个位置
- 表长加一
- 删除元素
- 判断删除位置是否合法
- 将第n到第i个位置的元素从前到后依次位移(这一步占据了最多的时间)有需要可以用一个变量接受被删除的元素,在之后作为返回值
- 表长减一
- 遍历元素